
티스토리 뷰
1. Introduce
현재 heap공부를 하고 있는데, 몇 주째 잡고있는데도 실력이 늘지 않는 것 같아서 직접 읽어본 자료들을 참고해서 malloc, free를 통해 chunk가 어떻게 할당되고 해제되는지, 그때의 chunk는 어떻게 구성되는지,free chunk들을 수용하는 bin들은 어떻게 구성되고 어떤 특징이 있는지 등등 여러가지를 설명하겠습니다.
(잘못 알고 있을 수 있는 부분이 있습니다. 댓글로 조언해주시면 감사하겠습니다 :D)
2. Explain
a = malloc(8);
b = malloc(8);
c = malloc(8);
이렇게 malloc을 진행하였다고 가정하고 chunk가 어떻게 할당되는지 보겠습니다.

malloc을 a,b,c 순서로 했으니 힙구조는 [C - B - A]가 될 것입니다.
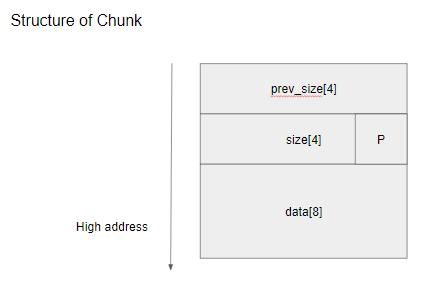
malloc 된 chunk의 구조를 살펴보겠습니다.
prev_size 필드
이전 chunk의 크기를 나타낸다. 이전 chunk가 free 되었을 때 설정됩니다.
size 필드
현재 chunk의 크기를 나타냅니다. malloc() 시에 설정되고, 하위 3비트는 특별한 용도로 사용됩니다.
PREV_INUSE 플래그
이전 chunk가 사용중인지 아닌지를 판별하는 플래그입니다.
만약 이전 chunk가 사용중이라면 1, free되어 있다면 0으로 설정됩니다.
IS_MMAPPED 플래그
해당 필드가 mmap() 시스템 콜을 통해 할당된 것인지를 나타냅니다.
mmap()으로 할당된 chunk는 약간 다른 방식으로 관리됩니다.
NON_MAIN_ARENA 플래그
multi thread application에서 각 thread 마다 다른 heap 영역을 사용하는 경우 현재 chunk가 main heap( arena)에 속하는지 여부를 나타냅니다.
data
말 그대로 입력한 값이 저장되는 영역입니다. AAAAAAAA가 들어가는 영역.

이번엔 free된 chunk의 구조를 살펴보겠습니다.
아까 살펴본 data부분이 바뀌었습니다.
fd(forward pointer)
아직 사용되지 않은 다음 chunk의 주소
bk(backward pointer)
아직 사용되지 않은 이전 chunk의 주소
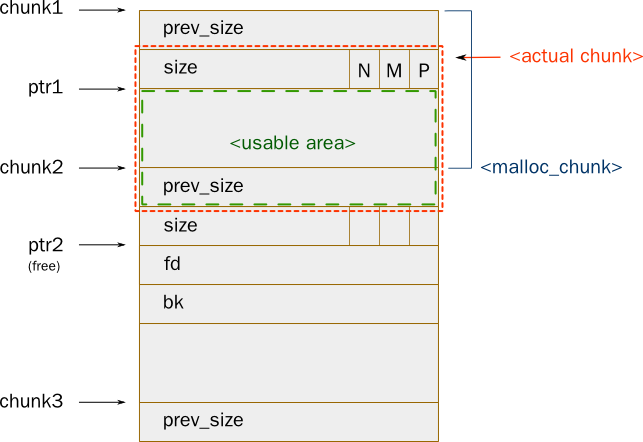
다른 그림을 통해서 free된 chunk의 구조를 더 자세히 설명하도록 하겠습니다.
저 그림에서 흥미로운 점이 하나있습니다. malloc 을 통해서 할당된 chunk는 prev_size, size , data필드 이렇게 구성되어 있는데, 다음 chunk의 prev_size 필드도 현재 chunk의 데이터 영역으로 사용된다는 것입니다.
사실 개념적으로도 이 부분도 현재 chunk에 속하며, free() 시에는 현재 chunk의 크기를 중복하여 저장하는 용도로 사용됩니다. (boundary tag 기법, 단 플래그들은 제외)
또한 free() 시에는 다음 chunk의 PREV_INUSE 플래그를 지워야하며, prev_size 필드는 오직 P플래그가 지워진 상태에서만 사용되어야 합니다.
heap은 영역을 할당하고 해제할 때, 메모리를 좀 더 효율적으로 사용하기 위해 bin이라는 구조를 사용하여 해제된 chunk list를 관리합니다.
이것을 bin구조라고 하고, free 된 chunk의 필드인 fd, bk를 이용하여 리스트를 연결하고 있습니다.
Bins
Bin은 freelist data structures이며, free chunk들을 수용하는데 사용합니다.
청크의 크기를 기준으로 사용하는 bin이 달라지게 됩니다.
Fast bin
Unsorted bin
Small bin
Large bin
Data structures는 이 bin들을 수용하는데 사용합니다.
fastbinsY - 이 배열은 fast bin을 수용합니다.
bins - 이 배열은 unsorted, small 그리고 large bin을 수용합니다.
Bin 1 - Unsorted bin
Bin 2 ~ Bin 63 - Small bin
Bin 64 ~ Bin 126 - Large bin
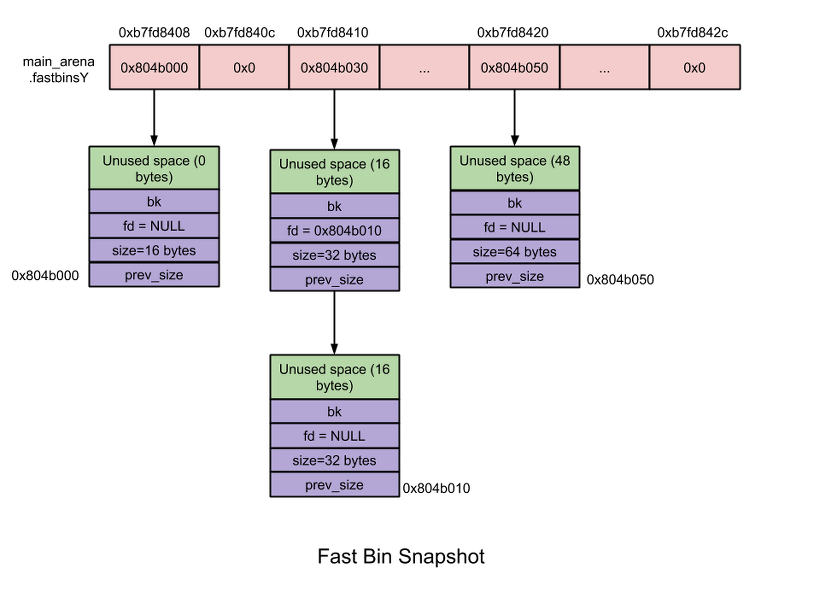
Fast bin
청크의 크기가 16~80 byte인 경우, fast chunk라고 부릅니다. fast chunk를 수용한 bin을 fast bin이라고 부릅니다. 모든 bin들 중 가운데, fast bin은 메모리 할당과 해제가 빠릅니다.
bin의 개수는 10개이고, 각 fast bin 은 free chunk로 구성된 단일 연결리스트(bin list)를 가집니다.
단일 연결리스트는 list의 중간으로 부터 fast bin chunk를 제거할 수 없기 때문에 사용됩니다.
chunk의 할당과 해제는 list의 앞쪽 끝에서 발생합니다.(LIFO구조)
Fast bin은 각 8byte 크기를 가지는 chunk의 binlist를 가집니다. 예를 들면 index 0의 fast bin은 16byte 크기의 chunk binlist를 가지고, index 1의 fast bin은 24byte 크기의 chunk binlist를 가지는 식으로 이어집니다. 또, fast bin 내부의 chunk는 동일한 크기입니다.
malloc 초기화에서, fast bin의 최대크기는 80byte가 아닌 64byte로 설정되어 있습니다. 따라서, 기본 chunk의 크기가 16 ~ 64 byte인 경우, fast chunk로 분류됩니다.
fast bin에서는 해제된 2개의 chunk가 서로 인접해 있을 수 있고, 단일 free chunk로 결합되지 않습니다.
malloc(fast chunk)
malloc을 할 때, 초기의 fast bin의 최대 크기와 fast bin index는 비어 있기 때문에, 사용자가 fast chunk를 요청하더라도 fast bin code가 아닌 small bin code가 이를 수행할 수 있습니다.
이후에, 비어있지 않게 되면 fast bin index는 해당하는 binlist로 부터 계산됩니다.
사용자가 malloc을 요청해서 chunk를 반환하게 되면, binlist의 첫번째 chunk가 삭제되고, 반환됩니다.(LIFO 구조)
free(fast chunk)
fast bin index는 해당하는 binlist로 부터 계산됩니다. 그리고 free chunk는 binlist의 앞쪽 위치에 추가됩니다.(LIFO 구조)
Unsorted Bin
각각의 bin에서 추가가 아닌 해제되는 경우, unsorted bin에 추가됩니다.
small 또는 large chunk들은 free가 됐다고 바로 해당 bin 리스트에 들어가는 것이 아니라 unsorted bin에 들어가게 되고, 메모리 할당시에 unsorted bin을 제일 먼저 확인하여 같은 크기의 chunk가 있다면 해당 chunk를 재사용합니다.
그리고 이 과정에서 한 번 검색을 거친 chunk들은 각자 자신이 속해야할 binlist로 들어가게 됩니다.
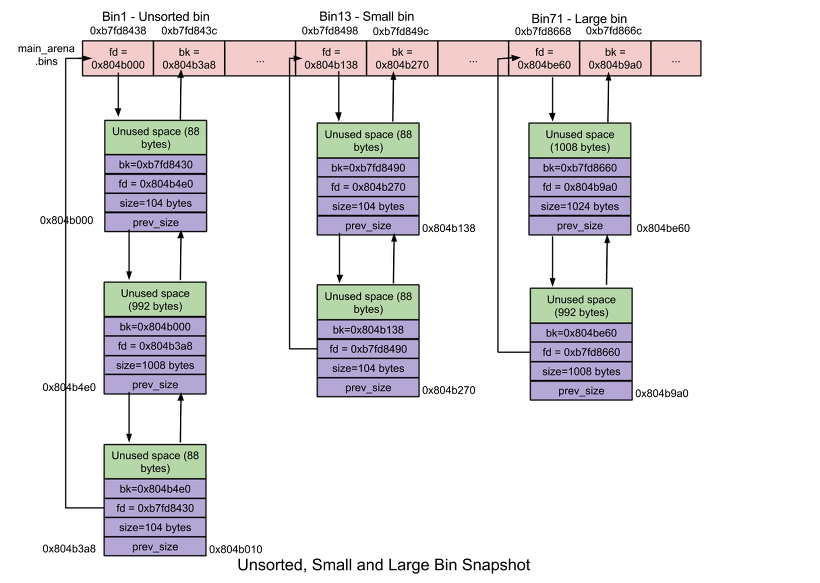
small bin
chunk의 크기가 512byte보다 작은 경우, small chunk라고 불립니다. small chunk를 수용하는 bin을 small bin이라고 부릅니다. small bin은 메모리 할당 및 반환이 large bin보다 빠릅니다. (fast bin보다는 느림)
bin의 개수는 62개로, 각 small bin은 free chunk로 구성된 원형 이중 연결리스트를 가집니다. 이중 연결리스트가 사용되는 이유는 list의 중간에서 small chunk를 제거할 수 있기 때문에 사용됩니다. chunk의 추가는 앞쪽 끝에서 발생하고 삭제는 list의 뒤쪽 끝에서 발생합니다.(FIFO 구조)
small bin은 각 8byte 크기를 가지는 chunk의 binlist를 가집니다. 예를 들면, 첫 번째 small bin(Bin 2)은 16byte 크기의 chunk binlist를 가지고, 두 번째 small bin(Bin 3)은 24byte 크기의 chunk binlist를 가지는 식으로 이어집니다. (fast bin은 small bin에 포함됩니다.)
또, small bin 내부의 chunk는 동일한 크기이며, 정렬이 필요없습니다.
binlist에서 해제된 2개의 chunk는 서로 인접해 있을 수 없으며, 하나의 free chunk로 결합됩니다.
malloc(small chunk)
초기의 모든 small bin은 비어있기 때문에, 사용자가 small chunk를 요청해도 small bin code대신에, unsorted bin code가 이를 수행할 수 있습니다.
또, malloc을 처음 호출할 경우, small bin과 large bin의 datastructures(bins)는 malloc_state가 초기화되어 있기 때문에 찾을 수 있습니다. bin이 비어있는 자기자신을 가르키고 있기 때문.
이후에 small bin이 비어있지 않게 되는 경우, 해당되는 binlist의 마지막 chunk는 제거된후, 사용자에게 반환됩니다.(FIFO구조)
free(small chunk)
현재 chunk를 해제하는 동안, 이전 또는 다음 chunk가 해제되어있는지를 확인하여, 해제된 경우 병합합니다. 각각의 binlist로부터 chunk를 제거하고 unsorted bin의 시작 부분에 새롭게 합병된 chunk를 추가합니다.
Large bin
chunk의 크기가 512byte와 같거나 큰 경우, large chunk라고 불립니다. large chunk를 수용하는 bin을 large bin이라고 부릅니다. large bin은 메모리 할당 및 반환이 small bin보다 느립니다.
bin의 개수는 63개로 각 large bin은 free chunk로 구성된 원형 이중 연결리스트를 가집니다. 이중 연결리스트를 사용하는 이유는 어느 위치에서나 large chunk를 추가하고 삭제할 수 있기 때문에 사용됩니다.
63개의 bins
32개의 bin은 각 64byte 크기를 가지는 chunk의 binlist를 가집니다. 예를 들면, 첫 번째 large bin(Bin 65)은 512byte ~ 568byte 크기의 binlist를 가지고, 두 번째 large bin(bin 66)은 576byte ~ 632byte 크기의 binlist를 가지는 식으로 이어집니다.
16개의 bin은 각 512byte 크기를 가지는 chunk의 binlist를 가집니다.
8개의 bin은 각 4,096byte 크기를 가지는 chunk의 binlist를 가집니다.
4개의 bin은 각 32,768byte 크기를 가지는 chunk의 binlist를 가집니다.
2개의 bin은 각 262,144byte 크기를 가지는 chunk의 binlist를 가집니다.
1개의 bin은 남은 크기를 가지는 chunk의 binlist를 가집니다.
small bin과는 다르게 chunk의 크기가 같지 않더라도 같은 범위에 속하면 같은 리스트로 관리합니다.
즉, 4KB를 위한 bin이 있다면 이는 정확히 4096byte 크기의 chunk만을 포함하는것이 아니라 4000, 4080, 3999 등의 크기를 가지는 chunk들도 포함한다는 것을 뜻합니다.
그리고 각 chunk들은 할당의 효율성을 위해 내림차순으로 정렬되어 저장됩니다. 가장 큰 chunk는 binlist의 가장 앞쪽에 저장되고, 가장 작은 chunk는 blinlist의 가장 뒷쪽에 저장됩니다.
이때 fd_nextsize와 bk_nextsize 필드가 이용되며 이들은 현재 bin 내에서 크기가 다른 첫 번째 chunk에 대한 포인터를 저장합니다.
또, 해제된 2개의 chunk는 서로 인접해 있을 수 없으며, 하나의 free chunk로 결합됩니다.
malloc(large chunk)
초기의 모든 large bin은 비어있기 때문에, 사용자가 large chunk를 요청했더라도, large bin code 대신 next largest bin code가 이를 수행할 수 있습니다.
또, malloc을 처음 호출할 경우, small bin과 large bin의 datastructures(bins)는 malloc_state가 초기화되어 있기 때문에 찾을 수 있습니다. bin이 비어있는 자기자신을 가르키고 있기 때문.
이후에 large bin이 비어있지 않을 때, 만약 사용자가 요청한 크기가 binlist의 맨 첫번째 chunk(largest chunk) 보다 작다면, binlist를 뒷쪽 끝부터 앞쪽 끝까지 확인하여, 사용자가 요청한 크기에 가깝거나 같은 크기의 chunk를 찾습니다.
찾게 되면, 해당 chunk는 2개의 chunk로 분리되고, 사용자가 요청한 크기의 chunk는 사용자에게 반환되고 나머지 크기는 unsorted bin에 추가됩니다.
또 다른 경우로, 사용자가 요청한 크기가 binlist의 맨 첫번째 chunk보다 크면, 비어있지 않은 next largest bin을 사용하여 사용자의 요청에 응답합니다.
next largest bin code는 비어있지 않은 next largest bin을 찾기 위해 binmaps를 스캔해서 해당하는 bin을 찾은 경우, 해당 binlist에서 적합한 chunk가 검색되고, 적합한 chunk를 분리하여 사용자에게 반환됩니다. 만약 찾지 못한 경우 top chunk를 사용하여 사용자의 요청에 응답합니다.
free(large bin)
small bin과 과정이 비슷해서 이 부분은 생략하도록 하겠습니다.
Top Chunk
arena의 가장 꼭대기에 있는 chunk를 Top Chunk라고 부릅니다. Top Chunk는 어떤 bin에도 속하지 않습니다.
Top Chunk는 bin들 중 하나에 해제된 chunk가 없는 경우, 사용자의 요청에 응답하기 위해 사용됩니다.
사용자가 요청한 크기가 Top chunk보다 작은 경우, Top chunk는 2개로 분리된다.
User Chunk(사용자가 요청한 크기)
Remainder Chunk(Top Chunk 크기 - 사용자가 요청한 크기 : 나머지 크기)
여기서 Remainder Chunk는 새로운 꼭대기 즉, 새로운 Top Chunk가 된다.
만약 사용자가 요청한 크기가 Top Chunk보다 큰 경우, sbrk(main arena) 또는 mmap(thread arena) syscall을 사용해 Top Chunk를 확장시킵니다.
Reference
http://tribal1012.tistory.com/78
http://egloos.zum.com/studyfoss/v/5206220
https://bpsecblog.wordpress.com/2016/10/06/heap_vuln/
- Total
- Today
- Yesterday
- 비교 연산자
- 리버싱
- darkknight
- 2025 청년도약
- C언어
- OllyDbg
- 청년도약계좌
- Golem
- 0ctf
- TAMUCTF
- 청년도약
- ftz
- succubus
- zombie_assassin
- BaskinRobins31
- Python
- Pwnable.kr
- 클래스
- babyheap
- 올리디버거
- bugbear
- HarekazeCTF
- orge
- 파이썬
- picoctf
- lob
- 포너블
- Codegate
- protostar
- Nightmare
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |