
티스토리 뷰
1. Introduce
heap을 얼마나 이해하고 있는지를 알기위해서 protostar의 heap시리즈의
write-up을 작성해보겠습니다. 제가 이해하기 위해서 쓰는 write-up이어서
설명이 길 수 있습니다.
2. Analysis
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | #include <stdlib.h> #include <unistd.h> #include <string.h> #include <sys/types.h> #include <stdio.h>
void winner() { printf("that wasn't too bad now, was it? @ %d\n", time(NULL)); }
int main(int argc, char **argv) { char *a, *b, *c;
a = malloc(32); b = malloc(32); c = malloc(32);
strcpy(a, argv[1]); strcpy(b, argv[2]); strcpy(c, argv[3]);
free(c); free(b); free(a);
printf("dynamite failed?\n"); } |
순서대로 a, b, c 에 32만큼 malloc을 해주고 역순서로 free를 해줍니다.
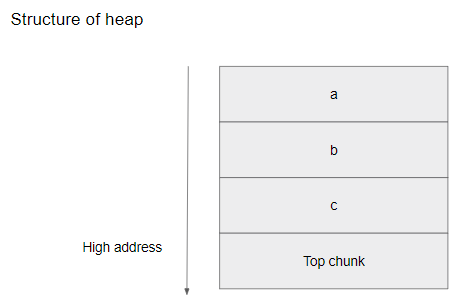
힙 구조는 위와같이 [C-B-A] 가 될 것입니다.
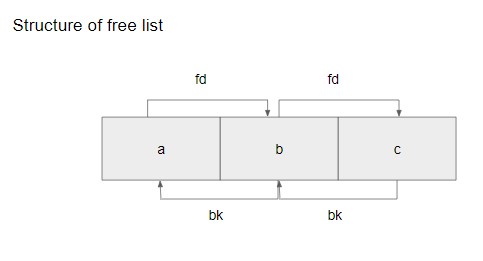
그리고 역순서로 free를 해줬으니 이런식으로 구조가 생길 것입니다.
구조가 이렇게 생겼다만 알고 바로 free 함수를 수행하면서 unlink 매크로를 설명하겠습니다.
1 2 3 4 5 6 | #define unlink( P, BK, FD ) { BK = P->bk; FD = P->fd; FD->bk = BK; BK->fd = FD; } |
이름만 들어도 무언가를 해제시키는 매크로 같죠? 맞습니다!
unlink 매크로를 그림으로 표현해 보겠습니다.
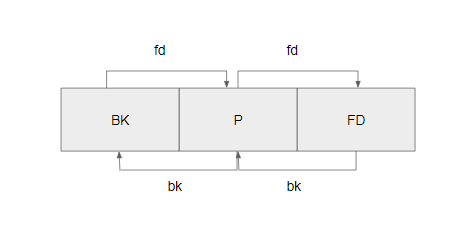
이런식으로 각 chunk들이 이중 연결 리스트로 연결되어 있을 것입니다.
그리고 P chunk를 free시킨다고 생각해 봅시다.
각 chunk들이 fd와 bk로 연결되어 있으니 그냥 막 free를 시킬 수는 없겠죠?

그래서 이렇게 P chunk의 다음 chunk와 이전 chunk의 fd와 bk를 이어주고 P chunk를 free합니다.
이 과정이 바로 unlink 매크로의 과정입니다!
unlink의 과정을 알았으니 어떤 경우에 unlink 매크로가 쓰이는지 알아보겠습니다.
1 . 현재 chunk의 이전 chunk나 다음 chunk가 free, 즉 사용중이지 않을 때 chunk를 합병할 때.
2. 중간에 있는 chunk를 free할 때.
저는 첫번째 경우의 unlink를 이용해서 exploit 해보겠습니다.
첫번째 경우에 chunk가 free되어있는지 아닌지는 size 필드의 PREV_INUSE 플래그를 이용해서 확인 한다고 했습니다. 이 부분은 제 블로그 포스팅을 보시면 자세히 설명되어 있습니다.
그렇다면 heap over flow를 이용해서 PREV_INUSE 플래그를 조작해주면 되겠지요?
그리고 unlink 매크로는 위와 같은 과정을 아래와 같은 식으로 변경할 수 있습니다.
FD = *P+8
BK = *P+12
FD + 12 = BK
BK + 8 = FD
FD+12 위치에는 BK가 들어가고 BK+8 위치에는 FD가 들어갑니다. 이를 이용해서 함수의 got를 바꾸거나, 소멸자를 바꾸면 프로그램의 흐름을 원하는대로 바꿀 수 있습니다.
3. Exploit
winner 함수를 실행시키는 것을 목표로 해야하니 주소를 구해줍시다.

그리고 puts_got를 조작할 것이니 got도 구해줍니다.
unlink 매크로를 이용해서 puts_got를 winner함수로 바꾸는 시나리오로 exploit 해보겠습니다.
unlink 매크로가 FD+12 = BK , BK+8 = FD 이런 식으로 계산을 하므로, puts_got-12 한 값을 FD에 넣어주면, puts_got-12 + 12 = BK 연산을 통해 puts_got = BK 가 들어가게 될 것입니다.
그리고 puts를 실행할 때 winner함수가 실행되겠지요.
payload에서 A를 32byte만큼 넣어주고 “\xfc\xff\xff\xff”를 넣어주는 것을 볼 수 있습니다. 이 부분은 다음 chunk의 prev_size와 size 필드인데요.
heap에서 chunk의 prev_size와 size 필드는 매우 중요한 부분인데요.
왜냐하면 이전 chunk의 주소와 다음 chunk의 주소를 prev_size와 size 필드를 이용해 계산하기 때문입니다.
예를 들자면, 현재 heap 구조가 [C - B - A] 라고 가정하고 free를 C, B, A 순서로 한다고 하면 free(c) 이후에 free(b)를 할 때 A chunk가 free 되었는지를 A chunk의 size필드의 플래그를 이용해서 확인하기 때문에 A chunk의 주소를 구해야합니다.
이전 chunk와 다음 chunk의 주소를 구하는 공식은 다음과 같습니다.
A chunk 의 주소 = &B - prev_size
C chunk의 주소 = &B + size
이렇게 계산을 하므로 prev_size의 값을 -4로 바꾸어 주게되면 0xfffffffc로 마지막 플래그들의 값이 모두 0으로 바뀌고, &B-(-4) 로 &B+4를 A chunk로 인식하게 될 것이고, &B+4는 데이터 필드이므로 FD, BK를 변조할 수 있게됩니다.
그래서 puts-got -12 값을 FD에 넣어주고, winner 함수를 BK에 넣어주었는데, 익스가 성공적으로 되지 않았습니다.
왜인지 살펴보았더니, winner+8 주소는 write가 불가능한 code영역에 BK를 넣으려고해서 Segmentation fault 오류가 떴었던 것입니다.
그래서 스택영역을 이용하기로 했습니다. puts_got를 우리가 제어할 수 있는 A chunk의 데이터필드 주소로 조작해주고, A chunk 데이터필드에는 winner 함수를 실행하는 코드를 넣어줍니다.
“\x68\x64\x88\x04\x08\xc3”
\x68 = PUSH
\xc3 = RET
winner 함수의 주소를 스택에 PUSH해주고 RET을 실행하게 되면 winner 함수가 실행되게 됩니다.

또 다른 방법으로는 jmp code를 이용하는 방법입니다.
BK + 8 = FD
때문에 BK+8 ~ BK + 12에는 FD의 값이 들어가 있어서 실행하다가 흐름이 끊길 수도 있어서 \xeb(jmp)를 이용해서 \x0c 만큼 건너뛰게 되면 \x90을 타고 winner함수를 실행하게 될 것 입니다.
질문 있으시면 댓글 달아주세요. 저에게도 도움이 됩니다 ㅎ
'Pwnable > Heap' 카테고리의 다른 글
| [Protostar] Heap2 (0) | 2018.03.11 |
|---|---|
| [Protostar] Heap1 (0) | 2018.03.11 |
| [Protostar] Heap0 (0) | 2018.03.11 |
| Heap 이해하기 (0) | 2018.03.11 |
- Total
- Today
- Yesterday
- succubus
- babyheap
- angry_doraemon
- Nightmare
- 비교 연산자
- babypwn
- zombie_assassin
- luckyzzang
- 클래스
- HarekazeCTF
- Pwnable.kr
- 올리디버거
- C언어
- darkknight
- ftz
- 포너블
- orge
- Golem
- OllyDbg
- protostar
- Python
- picoctf
- BaskinRobins31
- 0ctf
- 파이썬
- bugbear
- lob
- Codegate
- TAMUCTF
- 리버싱
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |